NOTE May 16, 2021: Some of the changes I made this morning broke the code for this exercise. I hope to release a working alpha version of my completed system within the next month or so, including a more robust mechanism for preserving exercise snapshots. Once I have that method in place I'll repair this example.
In this exercise, we're going to deploy the blogging system I use on this site. To follow along, you'll need to have already completed the first exercise and gotten a domain name. We'll delete the whole system at the end of the exercise, but if you'd like to keep using it you can. The infrastructure that we're going to deploy in this exercise will probably cost around $0.30 / month to operate; added to the cost of the hosted zone we deployed as part of the domain name exercise, that will bring the total cost per month to around $0.80. All of this infrastructure is billed on pay-as-you-go terms, so if you finish this exercise in one sitting, you'll probably not be charged for any of it.
Overview
In the first practitioner-inn post, I presented two ways of looking at personal social media systems; one based on function and another based on where important parts of state are held. In the functional view, this blogging platform is part of the website system. In the state view, this system is designed to hold artifacts of convenience--disposable, autogenerated items in display formats like HTML. In future posts, we'll deploy a visibility system and a special bucket to hold artifacts of human attention--kind of like a personal home directory in the cloud, where we keep original copies of things that we want to back up carefully.
The first few steps in the following instructions are about setting up the instance, and are the same as in the first exercise.
Instructions
Just like we did in the first exercise, we're going to start and set up a VM to run terraform. Go to the instances page and click the Launch Instances button. On the next screen we're going to choose the amazon machine image (AMI) that we want to use. A machine image is like a snapshot of a particular type of operating system, like MacOs, Linux, or Windows. Scroll down until you see an image called "Ubuntu Server 20.04 LTS." Click "Select," leaving the radio button set to "64-bit(x86)"
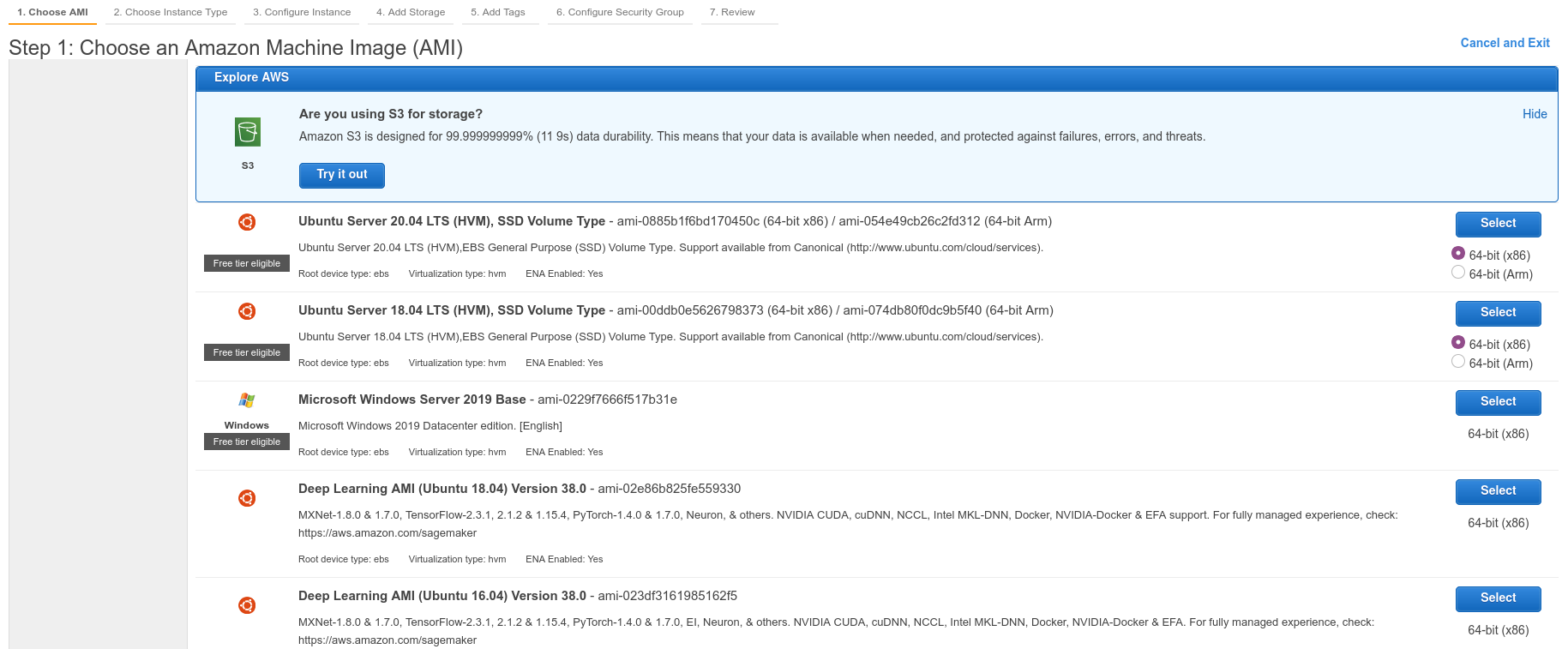
On the next page, leave the instance-size setting at t2.micro (notice that this is a computer with 25% of the memory of
a current iPhone) and click the grey "Configure Instance Details" button. The next page has a lot of settings, but we only need
to change one of them. On the IAM Role dropdown, select the administrator role that you created in the first exercise.
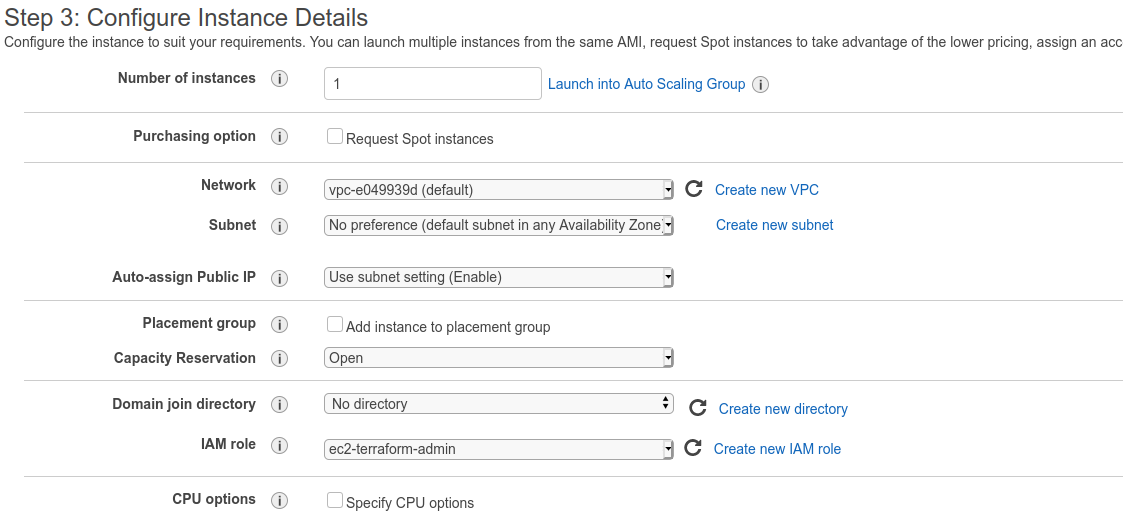
We don't need to change any more settings. Click the blue "Review and Launch" button at the bottom of the screen. On the next page, click Launch. On the popup, choose "Proceed without a a key pair" from the options, click the checkbox, and launch the instance.
Back on the instances page, you should see that your instance is starting up. Click on its ID, and at the top of the table click "Connect." When the instance is first starting, there's a short time (under a minute) when you can't click "Connect" so if it's disabled at first give it a few seconds.
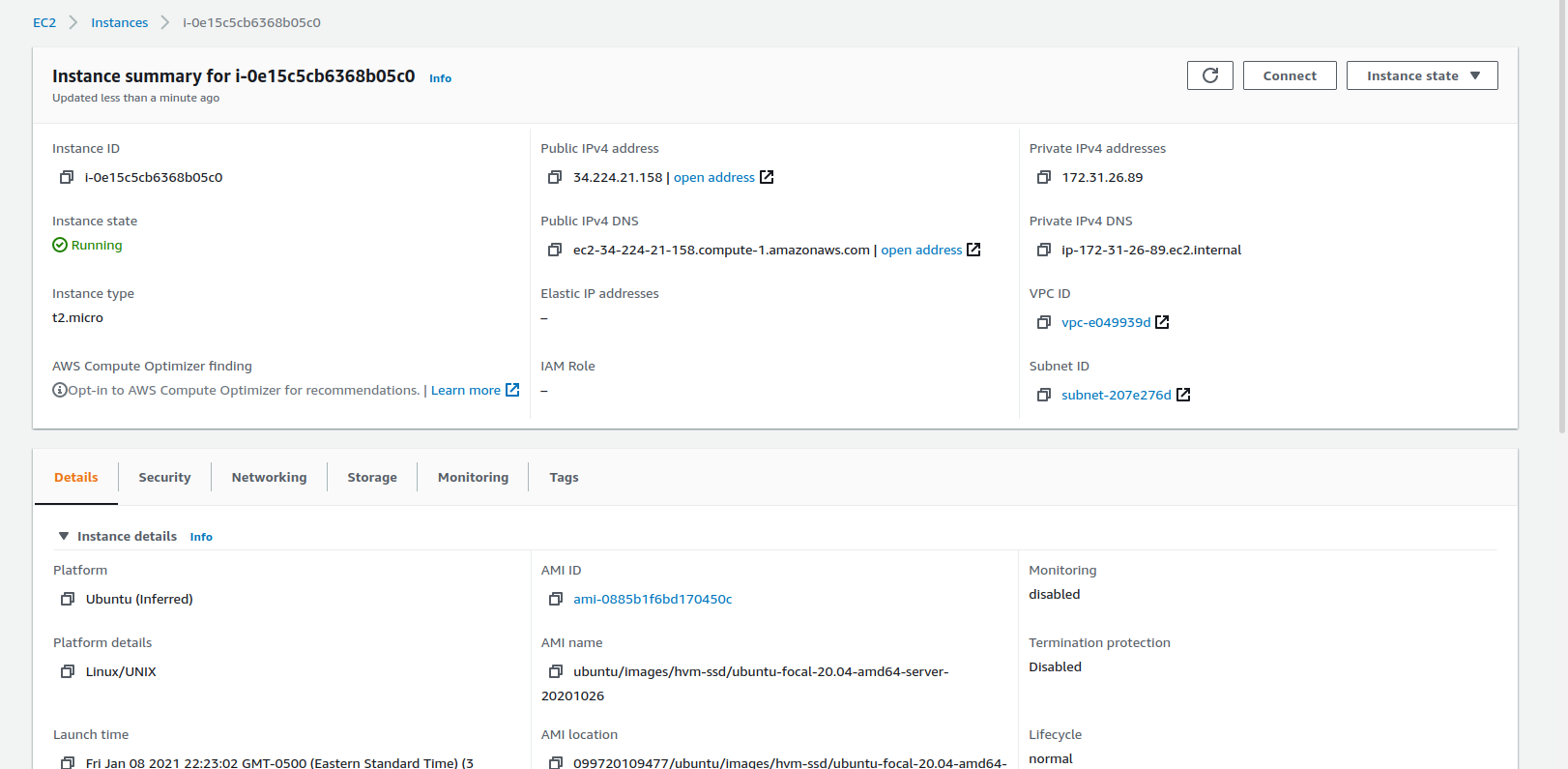
The next screen presents options for connecting. We're going to use the default of EC2 Instance connect, so just click the orange "Connect" button under the "Connect To Instance" panel. You should see a screen that looks about like this:
For the next few steps, I'm going to describe the commands you need to run and also provide
screenshots of what the output looks like. I've tried to make sure that I included the full text of each command.
When in doubt, use the screenshots to see exactly what I typed. Also note that the console tends to get
disconnected (the UI will freeze and you'll have to re-login through the "Connect" page on the instance)
if it is idle for more than about 5 minutes. If this happens, log back in and repeat any commands starting with
"cd" to get back to the right directory.
Before we can run terraform, we need to install it. Actually, we need to install a few things using a script.
A script is a short program we run at the command line. They often take care of housekeeping tasks like setting up an instance. But scripts can do just about anything, so you shouldn't run any script unless you understand exactly what it does. The script we're going to use is linked above, and it has comments explaining what it does.
We're going to download the script using git. Copy and paste the following command and enter it:
git clone https://github.com/RLuckom/practitioner-journey.git
If you ever mistype a command, you can press Ctrl-C to cancel the command you're on without entering it. It's also fine to close the window and log in again through the Instances page.
Now we're going to use cd to change directory into the directory the script is in. Enter the instruction:
cd practitioner-journey/004/
We're going to run a script called setup.sh. This script requires elevated
permissions, so we're going to run it as the super user with the following command:
sudo ./setup.sh
The last step in the script asks you to enter the name of the S3 bucket you made in the first exercise for the terraform state. Type in the bucket name and press Return.
If you make a mistake entering the bucket, you can run the script again the same way and enter the right name.
Next, enter the command
cd terraform
to move into the "terraform" directory, then enter
terraform init
to set up terraform.
Now you're going to set up the infrastructure. The command below shows every option you can specify,
but the only one that needs to be specified is -var='domain_name=${your domain}'. For the site_title,
use underscores (_) instead of spaces; they'll be converted automatically. You will probably want to copy
the whole command into a text editor and edit it there to replace my values with yours, then paste it onto the
command line. The slashes at the end of each line except the last allow you to just paste the whole command onto
the command line in one go. Avoid word processors like Microsoft Word (Is it still called that?) or Google Docs.
terraform apply -var='domain_name=raphaelluckom.com' \
-var='twitter_handle=RLuckom' \
-var='linkedin_handle=raphaelluckom' \
-var='instagram_handle=rluckom' \
-var='github_handle=rluckom' \
-var='site_title=Test_Website'
In this step, terraform is going to create the infrastructure. You will see a plan that creates 75 resources, modifies 0, and deletes 0. Type "yes" at the prompt to accept, and press Enter. This step will probably take 3-5 minutes to finish, and when it's complete you should see something like the following:
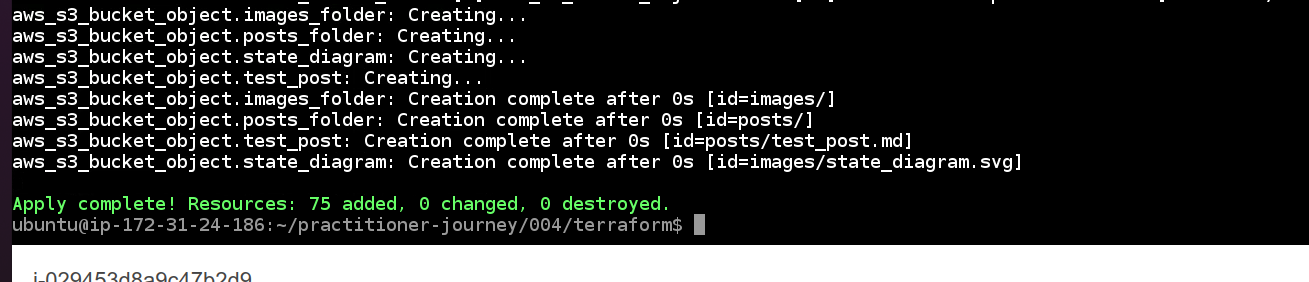
When this finishes, you should be able to go to the domain you reserved and see something like the following (It may take up to 20 minutes or so after terraform finishes before your site resolves in a browser. This is because of the way the internet "phone book" works--it takes time for the relevant systems to learn that new urls are available. One thing you can do to speed up the process somewhat is to wait a little while before going to your site for the first time. These systems can be pretty lazy--if they check once and don't find anything, they "remember" that there's nothing there and don't actually check again until some amount of time has passed. This is called caching, and it is the cause of and solution to many problems.):
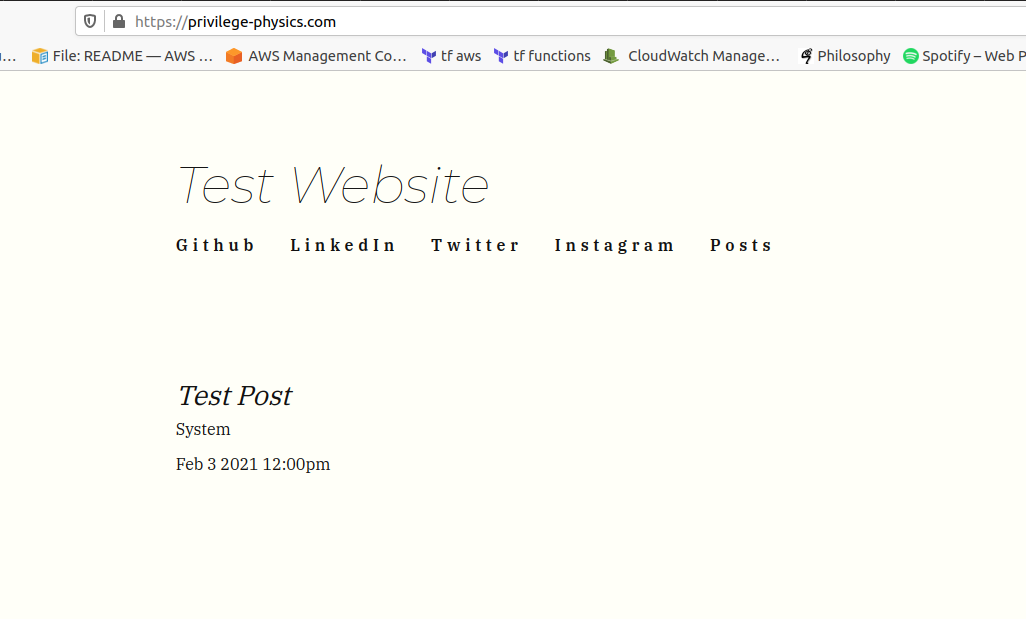
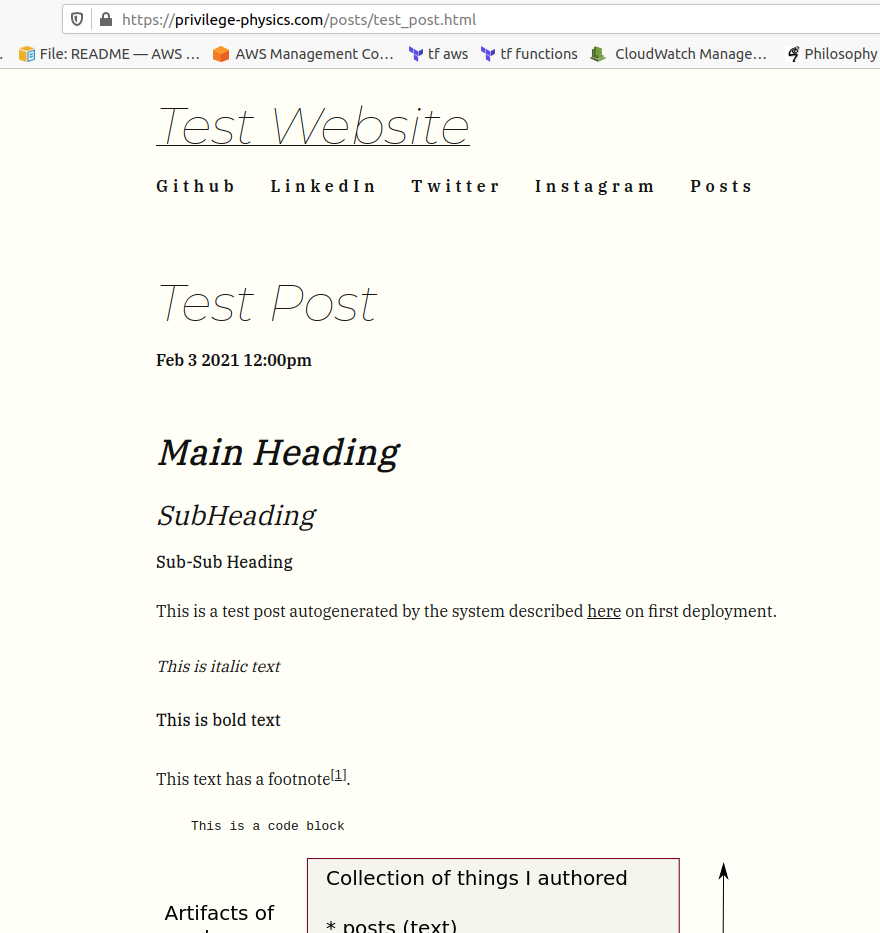
And the post should look like this:
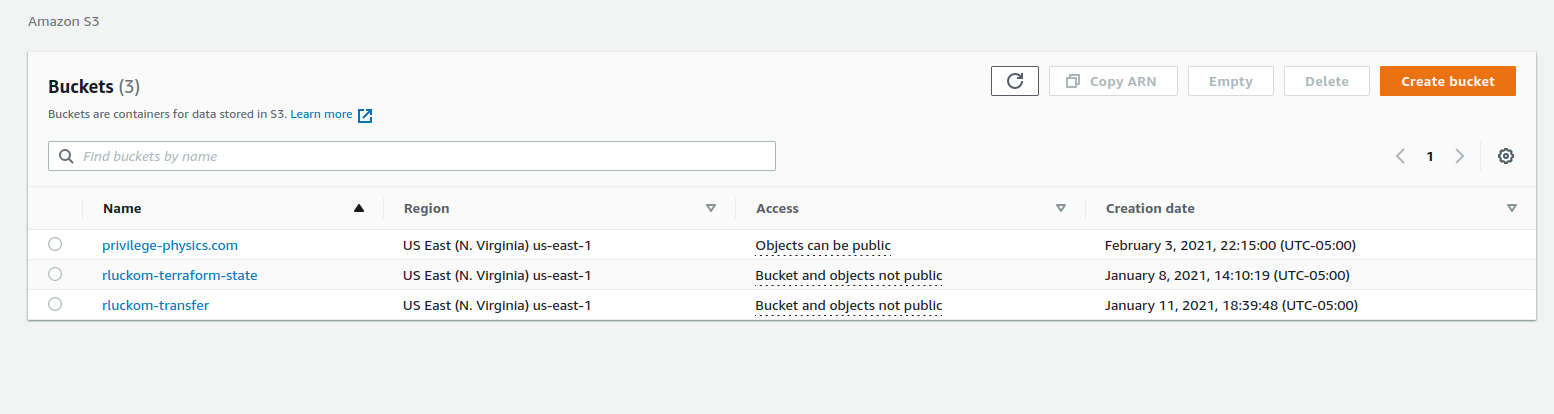
In the S3 console, you should see a bucket with the same name as your domain:
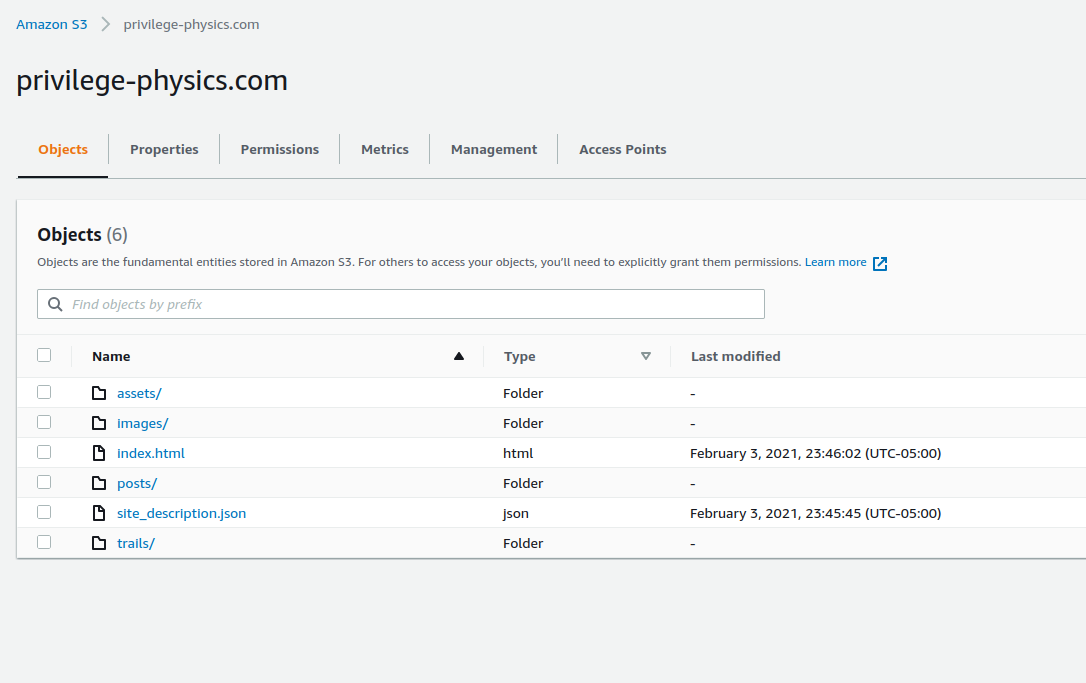
The S3 console presents the contents of the bucket as if they were in a directory structure[1]
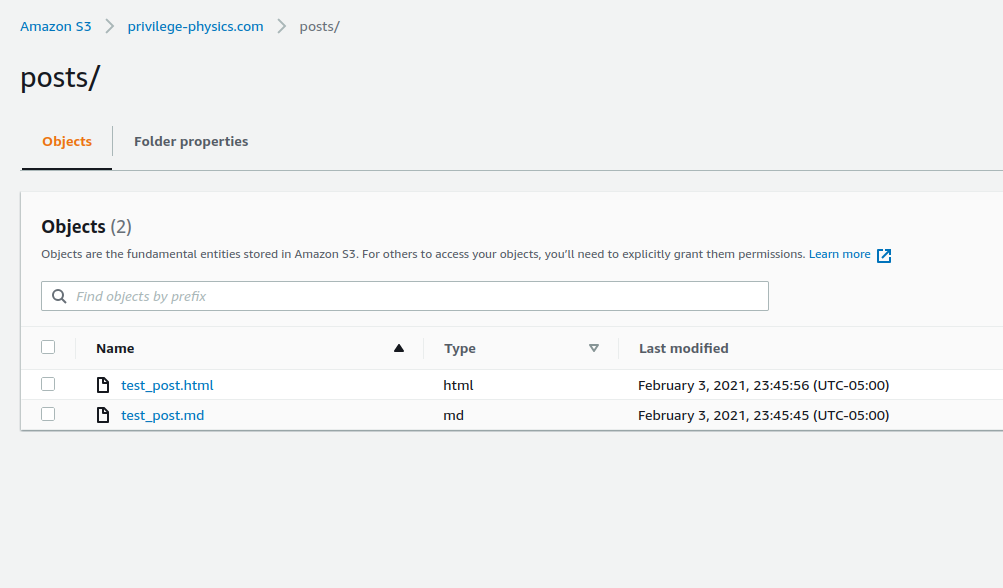
Within the posts folder you should see two files, test_post.md and test_post.html.
You can download the post.md file using the S3 console
The file looks exactly like this:
---
title: "Test Post"
author: "System"
date: 2021-02-03T12:00:00
meta:
trail:
- test
- cloud
---
## Main Heading
### SubHeading
#### Sub-Sub Heading
This is a test post autogenerated by the system described [here](https://raphaelluckom.com/posts/practitioner_journey_004.html)
on first deployment.
_This is italic text_
__This is bold text__
This text has a footnote[^1].

This is a numbered list:
1. First item
2. Second item
This is a bullet list
* First item
* Second item
This is a regular paragraph
> This is a block quote
[^1]: This is the text of the footnote
It spans multiple lines.
> You can even include a pull quote
The way that you post to this blog is by adding a markdown file to the posts directory. When you
do, an HTML file is automatically added to the site, and the post is added to the posts trail
(which is the same as the front page) and any other trails under the trail header in the front
matter. I'll go over this format in a little more detail in future posts. Note that the image
in the example post is the one in the images folder in the bucket. Any image in that folder
can be included in a post if it's referenced in the same way. When you delete one of the .md files
in the posts folder, the corresponding HTML file is removed and the list pages are updated to
remove the links. To modify a post, simply modify the .md file and re-upload it; the HTML
will be re-rendered. To change the site title or any of the social links, re-run the terraform apply
command with the updated values. They'll be updated when the pages are next re-rendered.
Now it's time to clean up the stack. I'll assume that you're restarting the connection to the instance. To get back into the terraform directory, you can use the instruction
cd practitioner-journey/004/terraform
When you're in the terraform directory, enter the following command to destroy the infrastructure we made today:
terraform destroy -var='domain_name=${your domain}'
You'll see a plan that deletes all 75 items we made today. Type yes at the prompt to confirm.
The first time you run this, terraform gets confused about the order and you'll see an error like
this:

Run the destroy command again the same way (you can use the arrow keys on the keyboard to get the previous commands) until it completes without error.
This was the last thing we needed this VM for. Close the connection window and terminate the instance using the Instance State dropdown on the instances list.

That's it for today. It's probably going to take a couple more posts to go into detail on each of the different areas of this system. If there's interest, I could go into more detail on the rendering system and the fairly basic theme system. If it doesn't seem like anyone's interested, I'll probably focus more on the visibility system, which hasn't yet made an appearance in these exercises.
Object-storage systems like S3 are key-value stores, which means that every file you upload is identified by a key. We often think of the key as a file path, because it often looks like
posts/myfile.md, and we're used to file systems as a way of hierarchically organizing data. The S3 console takes advantage of this to provide a file-system-like interface. This is a useful way to think about it most of the time, so I'll often refer to "folders" or "directories" in the context of s3 paths. ↩︎